常時パケットキャプチャ取得・分析ツール「Sonarman」を評価してみました。
いつもお世話になっております。たてまつさんです。
GW前に、Twitterでもいろいろとお世話になっている黒ブラさん ( 黒ブラ (@Clorets8lack) / Twitter ) が開発・販売されている、 Sonarmanをお借りして評価してみました。
今回は、現行バージョン「ver 1.5.6」で使ってみたレポートを書かせていただきます。
なお、直近でバージョンアップを予定されているとのことで、今回の評価レポートが空振りになる可能性もあります。予めご了承ください。
【お詫び】 骨折での入院というトラブルもあり、ここまで評価レポートが遅くなった点、返却期限が過ぎてしまった点について、 改めてお詫びします。申し訳ありませんでした。
評価レポートサマリ
- Sonarmanは日常トラフィックとの偏差をもとにトラブルシュートを行うためには非常に使い勝手の良いツールでした。
- 新バージョン楽しみにしてます。
- ネットワークエンジニアは総合力。Wiresharkなどのキャプチャツールを使いこなしましょう。
- 一言に「パケットキャプチャで分析」といっても目的や環境によってアプローチが異なることが実感できました。
公式HP
こちらがSonarmanの公式HPになります。 develup-japan.co.jp
検証環境の構成について
以下のような検証専用環境で評価を行いました。Sonarmanは赤色の箇所です。
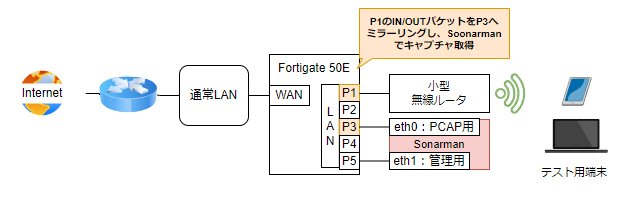
- FortigateのWAN側ポートに家庭内ネットワークを接続
- FortigateでNAT変換することで家庭内ネットワークは構成変更なしで利用
- FortigateのLAN側ポートに以下の2種類のデバイスを接続
- Sonarman
- 2つあるNICを各々接続
- 小型無線AP(ブリッジモード)
- Sonarman
- Fortigateのポートミラー設定で小型無線APの物理ポートでやり取りされるトラフィックをSonarman側のキャプチャ用NICへ転送
- 上記状態で、検証用のデバイスを小型無線APに接続し、検証用のデバイスを操作
ハードウェアについて
お借りした筐体はHP上に記載のあるものとは異なり、小型ベアボーンでおなじみの「Shuttle」製のものでした。
こちらも、冒頭に書いたバージョンアップに合わせてモデルチェンジを計画されているとのこと。楽しみですね。
是非USB Type-CのPDに対応したものにしていただけると、取り回しが楽になるので嬉しいです。
画面構成について
現バージョン「ver 1.5.6」は、基本的にWebIFで操作を行います。 ログイン直後の画面は以下のようなレイアウトになっていました。
なお、OSへのログインも解放されています。コンソール接続、SSH接続も可能。
ただ、起動時に流れてくるブート画面に表示される文字列や、ログイン後に使われているOSバージョンを見て「これは…」となりましたw
バージョンアップ、よろしくお願いします。
メニュー構造と機能の紹介
メニューの構造はこのような形になっています。
今回は、この中からいくつかポイントを絞って★マークの箇所をご紹介します。
- 機器情報
- キャプチャ★
- Syslog退避
- リングバッファ★
- 設定
- キャプチャファイル
- パスワード
- サポート
- VPN設定
- データ分析★
- I/O Graph
- I/O Data Export
- データベースダウンロード
- 閾値設定★
- 警告レベル設定★
- 通知設定
- DB行数制限
- 統計グループ条件設定
- ユーザー定義項目★
- 追跡
- Mac Tracking
- IP Tracking
- Trend
- Report
- 比較
- detail
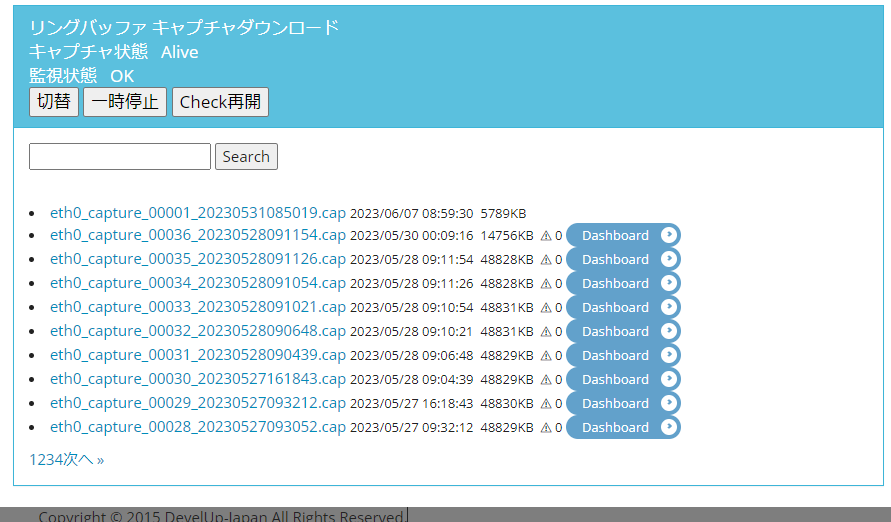
キャプチャ>リングバッファ
一覧
現在Sonarman内に蓄積されているキャプチャファイルの一覧が表示されます。
ここから分割単位でPCAPファイルを直接ダウンロードできます。 加えて、この箇所でキャプチャ機能の停止・再開などをコントロールできます。
各キャプチャファイルの横にある「Dashboard」ボタンをクリックすると、 該当のPCAPファイルに関するダッシュボードが表示されます。
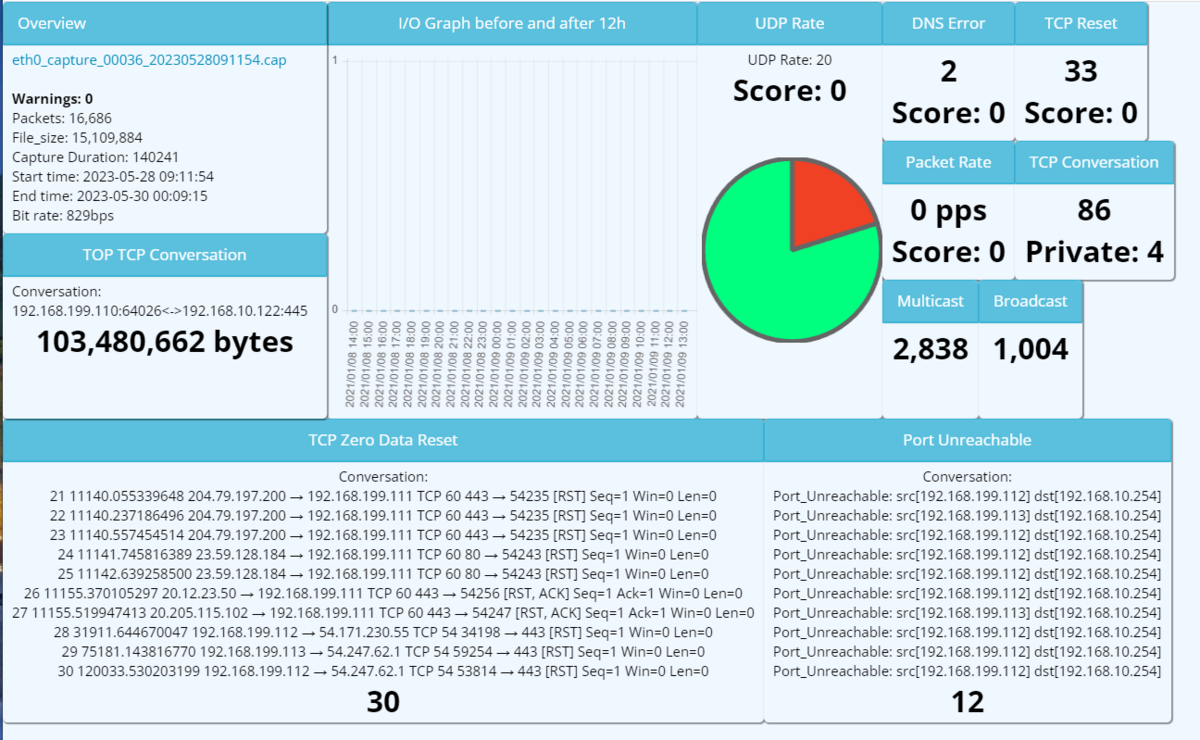
ダッシュボード
この「ダッシュボード」機能がSonarmanの一番のポイントだと思います。
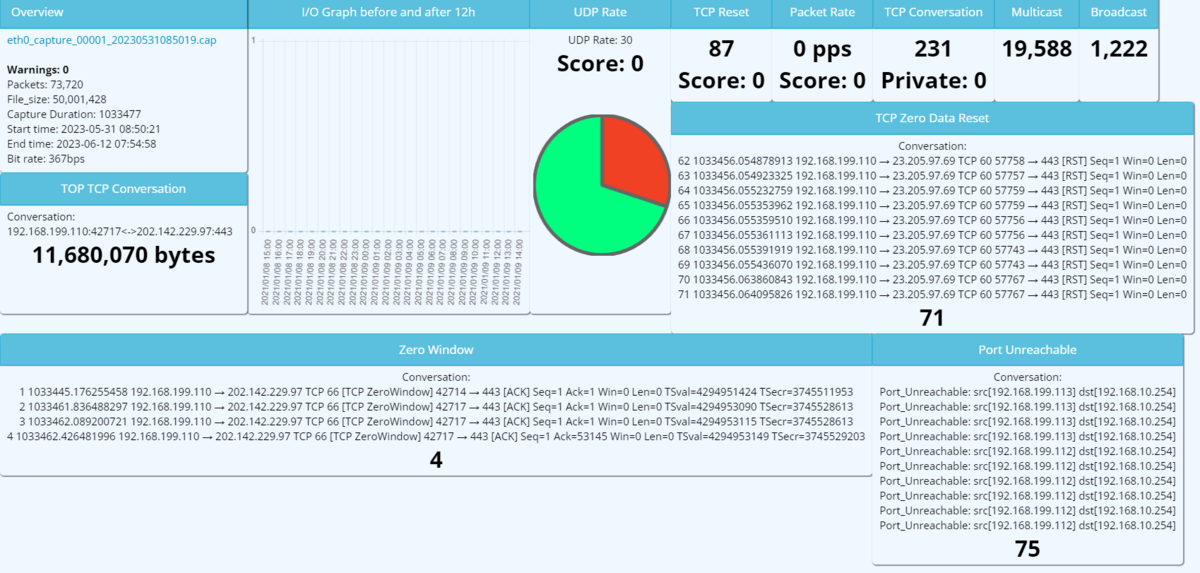
このダッシュボードには、PCAPファイル内に含まれる情報が、プリセットされた項目ごとに表示されます。 プリセットされた項目には、一例として以下のようなものが存在します。
- OverView:データの開始時間、終了時間やビットレート
- TOP TCP Connection:流量の多いTCPコネクションのTOP10の情報
- Broadcast/Multicast:ブロードキャスト、マルチキャストパケットの統計値
また、プリセットされたもの以外にも、後述する「閾値設定」「警告レベル設定」「ユーザー定義項目」で指定した条件を満たすと、その情報がダッシュボードに表示されます。
そのため、適切な閾値や警告レベルを定義することで、設置環境の問題の傾向がスピーディに把握できるようになっています。
利用方法の想定としては、以下の形かなと推測しました。
- 事前準備
- Sonarmanを設置する
- 設置環境上に日常的に流れるデータを蓄積する
- 蓄積されたデータの傾向から、「閾値設定」「警告レベル設定」をチューニングする
- トラブル発生
常時キャプチャで傾向を分析しながら素早く問題にリーチする、という材料として必要な機能を備えていると感じました。
【実例1】
【実例2】
データ分析
閾値設定
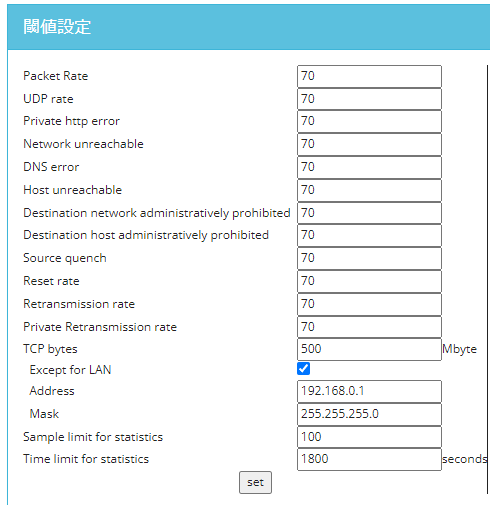
ここでは、ダッシュボードへの警告表示や、メール通知(今回未記載)の条件とするため、プリセットされた各種パラメータを調整できます。
プリセットのパラメータを見ていると「unreachable」系のものが多く、やはり「○○できない」という時にはこのあたりを見ますよね~とうなずきながら画面を眺めていました。
なお、ここで定義できるパラメータは多くが「偏差」の値です。偏差とは、平均値との差のことをいいます。普段のトラフィックデータ内のカウンタが別でデータベースに保存されており、そこで平均値が都度算出されているようです。
その平均値から大きく乖離するような場合に警告を出す、という作りになっています。
警告レベル設定
先ほどの閾値設定と項目が似ていますが、ここではその閾値を超えた各カウント対象ごとのイベントについて、重みづけをするような箇所になります。
ここでの数値が10を超えた場合、メール通知やダッシュボード上での警告表示など、より緊急性の高いイベントとして扱われます。
また、画面を見ていただくとわかりますが、ここでは閾値設定の箇所になかったパラメータとして、BitTorrentやDHCP NAK(アドレスが取得できなかった)というようなパラメータもあります。
パケットの中身をある程度解析したものを警告に活用できる、非常に便利な機能ですね。

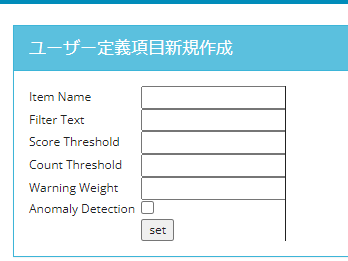
ユーザー定義項目
ここでは、プリセットされていない項目について、ユーザ自身で定義してダッシュボードに表示したり、警告のアクションに加えることができます。
「Filter text」の箇所で対象を特定する書式を入力します。この書式はtshark形式のため、WiresharkのGUIでのフィルタ書式とは若干異なります。
- 例:【ホスト「192.168.1.1、TCP80」に該当する通信】を示すフィルタ
- tshark形式:
host 192.168.1.1 and tcp port 80 - GUI上フィルタ形式:
ip.addr==192.168.1.1 && tcp.port==80
- tshark形式:
任意の条件で自動で検知やダッシュボードへの警告が出せるため、環境によって異なる検知条件だった場合でも、有効活用できます。
所感
ネットワーク関連のトラブルで発生しがちな症状をとらえるための手段として、非常に有効活用できるツールだと思います。
「なんか最近LANが遅いんだよね…」みたいな症状が起こりがちな環境で、パケットキャプチャを取って漠然と眺めてみても、真因にたどり着くことはなかなか難しいです。
Sonarmanを活用すると、普段の値との偏差から直近のトラフィックの傾向がつかめるようになります。
例えば「やたらDNSエラーが増えてる」とか「先週と比べてUnreachable系のパケットが増えている」というように、具体的な変化の傾向をキーにして、いち早く問題解決することができそうです。
ただ、その普段の値と比較して異常な状態になっていたとして、「DNSエラーの対象はどこなのか」という点は具体的にPCAPの中身を見ないと確認できませんし、「どうすれば治るか」という点については症状や環境によりけりです。また、変化が大きかったからと言って、それが本当に問題につながっているとは限りません。
パケットキャプチャを利用したトラブルシューティングを行うためには、キャプチャを取得した環境に対する理解が必要です。そして、これはネットワークエンジニアの得意なL2/L3の領域だけでなく、ある程度クライアント~サーバシステムの知識が必要になります。
そういう意味では、ネットワーク領域だけでなく、ITシステムに関する総合的な知識を持ったエンジニアでないと使いこなせないな、とも感じました。
やはり、ネットワークエンジニアは総合力が重要ですね。
あるといいな、と思った機能について
前職で、私は常時パケットキャプチャ取得機能を持ったITサービスの環境を設計・構築・運用・保守してきました。
そこで利用していた機能や、そのキャプチャデータの分析で活用していた手法をベースに、こんな機能があるといいな、という妄想をいろいろと書いてみます。
保有PCAPデータの総合ダッシュボード機能
現在、ダッシュボードの機能は各PCAPファイル単位で提供されています。
半面、内部に保存されているPCAPファイル全体を使ったサマライズ機能は無いように見えています。※機能把握が浅いだけであれば申し訳ありません。
よくあるシーンとして、「今月一か月間でのサマリを見るとどうなるかな…」というケースがあります。
現在の「Trend>Report」の機能がこれに該当しますが、表示内容が限られており、ダッシュボードよりは少ない状態です。
日付指定で腹持ちしているデータを活用して、個別ダッシュボードと同様の表示が生成できるような、総合ダッシュボード機能があると嬉しいなと感じました。
From/Toの時間指定でのPCAPデータ抽出機能
現在、分割単位でパケットデータが保存されています。
この中から特定の期間のデータを抽出しようとすると、複数ファイルを手元にDLし、それらをマージ、前後をカットする、という作業が必要になります。
From/Toの時間を指定して、分割単位のパケットデータから、マージされた1つのPCAPファイルをDLできるような機能があると良いなと感じました。
PCAPダウンロード時点でのフィルタリング機能
パケットキャプチャの取得時には、原則としてフィルタリングを行うことはないと思います。理由としては、「見たいものを探す」ためにパケットキャプチャするのではなく、「見えていないものを探す」ためにパケットキャプチャするからです。
ただ、ある程度ダッシュボードなどで傾向が見えた際には、そのデータのみを抽出したい、というようなケースも多いと思います。
上記の時間指定でのデータ抽出に合わせて、指定文字列でのフィルタをかけたPCAP抽出ができると良いなと感じました。
ユーザ指定のIPリストや、外部IPリストにマッチしたデータのサマライズ機能
昨今、ITシステムの中でSaaSなどを利用するケースも多いと思います。
そして、そのSaaSに関するトラブルがあった際、SaaSに関するパケットの傾向をつかみたい、というような場合も多いと思います。
SaaSはIPアドレスが変動しがちですが、SaaSによっては利用しているIPアドレス情報をホームページ上に掲載しているものも多く存在します。
それらの情報をテキスト情報として取り込み、各SaaSに対してのトラフィックの傾向をつかむ、というような機能があるといいなと感じました。
txt形式のIP羅列だけでなく、json形式でのデータ取り込みもできるとさらにうれしいです。(チラッチラッ)
※こういうデータを自ら作るためには、MineMeldといったOSSツールなどが活用できます。 過去にMineMeld環境を構築した記事もありますので、良ければご参照ください。 https://tenko.hatenablog.jp/entry/2020/07/05/124300
Coversationの可視化(グラフ表示)機能
現在ダッシュボードが備えている流量に関する機能は、流量の多い通信のTOP10のセッション情報を出す、という機能です。
私がパケットキャプチャのトリアージ段階でよく利用する機能として「Conversation(対話)」の機能があります。
そこでよくやるオペレーションとして、送信元:宛先アドレス(A/B)のIPアドレスやセッション毎のPacketByteやDurationのデータを見ながら、解析対象時間内のデータ傾向をつかみ、フォーカスするセッションのデータをピックアップすることが多いです。
そういう情報が、ダッシュボードの中で可視化されていると非常に分析が早くなるなと感じました。
メニュー階層構造の見直し
これは機能追加という形ではないのですが、「設定」に入りそうなものが「分析」の中に入っていたりなど、少しメニューの構造が直感的でないように感じました。
リモートサポートとのセットが多い、という性質もあり、Sonarmanの画面自体を見るユーザは少ないかもしれませんが、メニューの階層構造を見直してみてもよいかもしれません。
大容量版やパケットデータの外部アーカイブ機能
やはりパケットキャプチャの生データを長期間保存しておきたい、というケースは多くあると思います。
Sonarmanの想定ユーザ外かもしれませんが、データ保存領域の拡大や、内部PCAPローテーション時の外部ストレージへのアーカイブ機能などがあると嬉しいなと感じました。
※前職では1分間で5GB程度の流量があるキャプチャを見ていたのでw
私とパケットキャプチャ(ポエム)
ここからは完全に蛇足です。
今回、このブログを書くにあたり、やはり一言で「パケットキャプチャを使った分析」といっても、アプローチは各々異なっていて面白いな、と感じました。
トラブルシュートのスタイルについて
パケットキャプチャをはじめとした、トラブルシュートについては以下の2種類のアプローチがあると思っています。
- 直感・経験値型
- 階層ごとの切り分け・データ分析型
前者は、これまでの業務経験などから、トラブルの症状に対して自身の中での経験値という名の辞書を参照し、トリアージを開始、原因分析をしていくパターンです。
後者は、実際の症状をパーツ単位で区切り、そのパーツ単位での切り分けや数値の傾向からトリアージを開始、消去法から原因分析をしていくパターンです。
Sonarmanは、後者寄りのアプローチからトラブルシュートをしていく際に非常に有効だなと感じました。
私は年齢を重ねたり、様々なシーンでパケットキャプチャでのトラブルシュートを行ってきた結果、前者寄りのアプローチをすることが多いです。
もちろん、「ただの勘」で分析することはなく、経験値からくる「嗅覚」のようなもので、症状に合わせて利用するパーツを切り替えながら、トラブルシュートをしてきました。
実例から見る、切り分けスタイルのトリアージだと解決が遅くなるケース
例えば、「データ転送が遅い」という症状のケースでは、以下のようなケースがありました。
- 他の端末や目的外のデータ通信が帯域などのリソースを占有した結果遅くなっていた。
- 経路上で全二重・半二重や速度のミスマッチがある環境があり、パケロスが非常に多く発生していた。
- 端末に接続されているLANケーブルは床下から出ていたが、その床下に10Base-Tのハブが眠っていた。
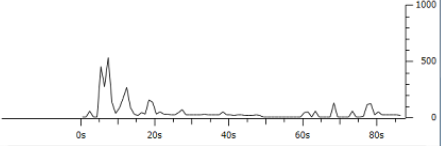
- クライアント~サーバ間で通信中にWindowSizeが小さくなっており、TCPのオーバーヘッドが発生しやすい環境となった結果、帯域を有効活用できていなかった。
前の3つは比較的あるあるかなと思いますが、4番目はしっかりとデータの中身を見ないと理由にたどり着けませんし、それを解消するにはどうすればいいか?という案も出てこないと思います。
過去に類似の事例があれば「これかもしれない」と思って見てみる人も中には居るかもしれませんが、教科書通りの分析を行ってもこのあたりはあまり登場しないと思います。
下から順に切り分けを進めていく場合、4番目のケースはなかなか根本原因にたどり着くまでに時間がかかります。
こういうケースのトラブルの場合、なかなかノウハウの共有が難しいなと常日頃から感じています。
ちなみに、4番目のケースはWiresharkだと「I/O graph」のデータを出すと、該当セッション内で時間経過毎にやり取りされたデータ量が可視化されるため、視覚的に状況を確認できます。(↓こういうやつ)
私のパケットキャプチャの分析スタイル
症状によって異なりますが、大体共通しているのは以下の流れです。
- 事前準備
- キャプチャの取得時はフィルタはかけない。
- 分割単位は200MB単位でファイルが分割されるようにする。
- スペック弱めのPCでもこの程度なら扱えるため
- 解析開始(トリアージ)
- 状況整理
- 大体の登場人物が見えてきたらシーケンス図を脳内に描く(アウトプットしろ)
- 脳内のシーケンス図とざっとみたデータでトラブルの箇所がどこかを推測し、仮説を立てる。
- 一般的なITシステムの動きと照らして仮説がトラブルの要因になりそうな場合、次へ進む。ハズレの場合は「これは違った」をメモに残し、トリアージや仮説に戻る。
- 仮説検証
- 実際のパケットデータに戻り、それが本当かを抽出する。
- このとき、必要に応じて除外した別のキャプチャデータも参照することもある。
- これが誤っている場合、再度トリアージに戻る
- ただし、「このケースは当てはまらなかった」は都度メモに残す、
- 実際のパケットデータに戻り、それが本当かを抽出する。
- 立証完了
- 仮説が立証されるパターンが見つかったら、初めてシーケンス図をアウトプットする。
- 上記に加え、原因や対処方法などをテキスト化しレポートにまとめる
こういう流れを高速でクルクル回す形のスタイルを取っています。そのため、解決までにはそれなりに時間がかかります。(そろそろAIに学習させて楽したいですね。)
こんなスタイルなので、中間成果物があまりないのが難点です。
パケットキャプチャに限らず、トラブルシュートは大体こういうスタイルで対応しています。
「原因がこうであってほしい」という色眼鏡で見ると、それが見つからなかったときに途方に暮れてしまいます。
そのため、あまり期待をもってトラシューに対応するのではなく、【本来こうあるべきもの】が【見たもの(ログやパケット)の中にある・ない】という個別の結果を、見えた都度自分の脳内カードにしまい、そのカードを組みあわせながらトラブルシュートをしています。
すごーくフワッとした表現をすると、「引いて、寄って、また引いて、こねくりまわして、角度変えてまた引いて寄って…」って説明しますw
人に教えるって難しいですね…